今天给大家推荐近期被CCS 2024接收的论文Certifiable Black-Box Attacks with Randomized Adversarial Examples: Breaking Defenses with Provable Confidence,文章由康涅狄格大学计算机工程Yuan Hong研究组与伊利诺伊理工学院浙大网络空间安全学院合作完成并投稿。

太长懒得看版本:本文研究一种针对通用机器学习模型的新型对抗性黑盒攻击。有别于传统攻击者构建的确定性的攻击样本,本文构建了基于概率分布的随机攻击样本,通过访问(query)目标模型收集统计信息,构造与更新攻击样本,从理论上保证了未访问过模型的随机攻击样本的攻击成功概率,可以做到随机样本未攻击就已知攻击成功概率。该攻击具有高度随机性与可验证的攻击成功概率,可以突破诸如Blacklight、RAND等针对黑盒攻击的强力检测、防御手段。
详细讲解的版本:
研究背景
机器学习(ML)模型虽取得巨大成功,却容易被微小的输入扰动(perturbation)干扰导致分类错误,特别是由恶意攻击者精心构造的扰动。有许多最先进的对抗性攻击被提出以探索各种机器学习模型的脆弱性,进一步帮助完善模型的安全性。攻击者通常通过访问(query)模型迭代改进手中的攻击样本,最终达到攻击目的(改变模型输出)。其中,严格的黑盒攻击只依赖模型的prediction score或者hard label进行攻击样本构建,被认为是更贴近实际安全实践的方法。
相较于该文即将提出的可验证攻击(certifiable attack),作者暂且把现有的黑盒攻击称为实践性攻击(empirical attack)。现有的黑盒攻击主要利用梯度估计、代理模型或启发式算法生成对抗性样本。尽管这些攻击算法能够在无防御的实践中达到较高的攻击成功率,但这些攻击被证明容易被检测而失效,因为它们通常有着较小的迭代更新步长(样本的更新连续而细微)。例如,Blacklight【1】能够通过检查query样本的相似性对大多数现有黑盒攻击达到100%检测率。为了突破这种针对实践性攻击的防御手段,一种简单的方案是对样本的更新加入随机噪声,使得query样本的相似性减小,但是另一个问题随之而来:随机噪声会导致攻击的效果和效率下降。通常来说,在样本的迭代过程中,下一个样本通常依赖于上一个样本进行改进,当加入的随机噪声过大时,样本之间的连续性可能会被破坏,上一个样本以及查询结果将失去借鉴的价值,下一个样本的表现也将变得不可预测。这种方式也被用于防御黑盒攻击,例如某些“随机防御”方法通过向输入、输出、中间特征或模型参数中注入随机噪声,从而使现有黑盒攻击的表现显著下降。总而言之,为了突破相似性检测作者尝试引入了随机性,然而这种随机性会导致攻击性能下降。
为了解决这个问题,该文提出了一种新的攻击范式,能够在随机噪声下保证攻击的理论成功概率,称为可验证攻击。首先,该文认为攻击样本是输入空间中的一个随机变量,该随机变量服从某个噪声分布φ, 称为“对抗性分布“(”Adversarial Distribution“),攻击样本可以从对抗性分布中采样得到。与之配套的是一种新的query方法,该方法采样随机攻击样本,query目标模型,并且返回统计信息。在此基础上,该文建立了理论来指导攻击构建,保证攻击的成功概率。从算法层面,该文构建了一个可验证攻击框架,包括多种算法来构建、更新对抗性分布。
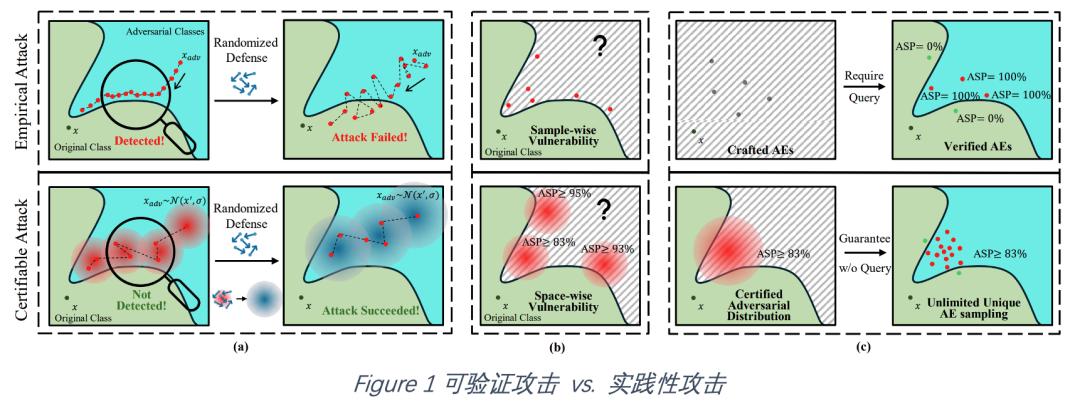
如图1所示,与现有的实践性黑盒攻击相比,可验证黑盒攻击展示了多方面的优势:
可验证黑盒攻击凭借随机噪声,可以突破基于query相似性的检测手段,如Blacklight等。与此相反,实践性黑盒攻击构造的连续query则容易被检测。与此同时,可验证黑盒攻击综合考虑了query的统计信息,这些信息中包含了目标模型的反馈以及可能的防御措施所带来的影响,因此所构建的随即攻击样本可以保证对目标模型及其防御的攻击成功率。
实践性黑盒攻击通常揭露模型对单一对抗性样本的脆弱性,与此不同,可验证黑盒攻击可揭露模型在连续对抗性输入空间的脆弱性。该对抗性空间由对抗性分布决定,可由此采样在此空间内生成无穷个对抗性样本,同时具有可验证的攻击成功率,展示了一种持续而严重的模型脆弱性。
基于query的实践性黑盒攻击通常迭代构造对抗性样本直到最新构造的样本成功或者达到query上限。在这个过程中,最终成功的样本必须经过模型的验证以确认成功,因此成功的样本将在模型或防御系统里留下记录,影响再次利用的可能。与此不同,可验证黑盒攻击提供了一种有攻击成功率保证且无需经过模型验证的攻击方式。在高维连续空间中,从对抗性分布中随机采样的样本具有可忽略不计的重复率,因此对模型而言,每个对抗性攻击样本都是全新的未被记录的。这些采样的攻击样本在无需模型验证的基础上保证了攻击成功率。
该文章在4个数据集上,4种防御手段下,与16种前沿黑盒攻击进行了大量对比,结果显示可验证攻击在不同的设定下性能均超过大部分黑盒攻击,特别是在Blacklight下,该方法在所有设定下的攻击检出率均为0%(其他黑盒攻击约为100%)。与此同时,该文章进行了大量消融实验以及在不同适应性防御下进行了验证。作者提供了一个完整的代码库(包含可验证攻击,16种前沿黑盒攻击,4种防御手段以及大量数据集、模型实现)以供复现。
代码可见于:https://github.com/datasec-lab/CertifiedAttack
研究方法
文章首先明确了可验证黑盒攻击的定义:
给定一个分类器
其中
为了给出错误分类概率(攻击成功概率)的下界, 该文章参考可验证防御中的随机平滑(randomized smoothing)设计了一种随机并行访问(Randomized Parallel Query):
给定一个攻击样本均值
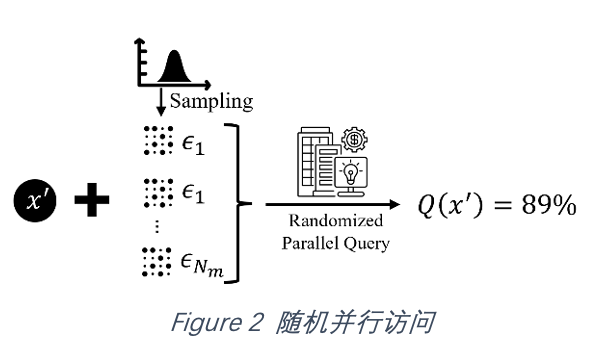
明确了攻击的目标以及访问的手段,可验证黑盒攻击可以通过图3的三个步骤构造满足要求的对抗样本:
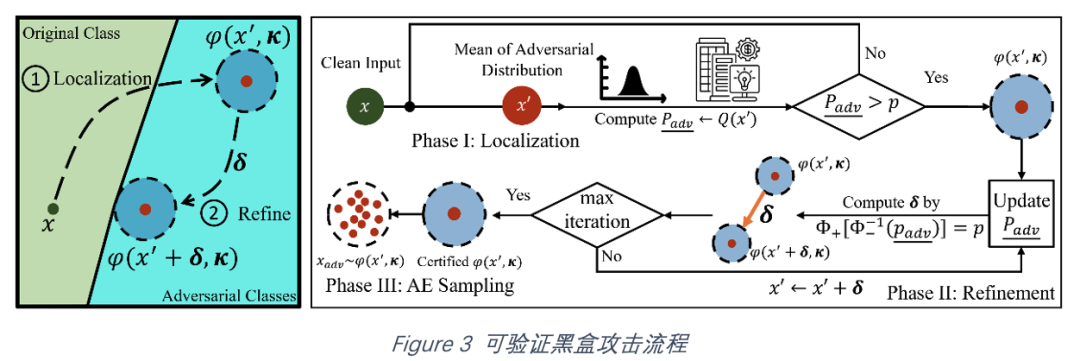
初始对抗性分布定位(Localization):给定一个正常样本,该方法首先寻找一个使得攻击成功率下界高于给定阈值的对抗性分布,称为Localization。最简单的Localization的方式是从输入空间中随机选取对抗性分布直到满足要求(随机定位)。除此以外,文章提出了两种更有效率的Localization的方法:平滑自监督扰动(Smoothed Self-supervised Perturbation)主要通过在代理模型(surrogate model)上构造无需标签的扰动来高效定位对抗性分布;二值搜索定位(Binary Search Localization)则是在随机定位的基础上通过二值搜索缩短与正常样本x的距离。
对抗性分布优化(Refinement):获得了满足攻击成功率阈值的对抗性分布后,该方法将继续移动对抗性分布中心以进一步减小扰动。文章建立了理论以界定均值移动的范围,在该范围内,攻击成功率下界将保持在阈值以上。在算法上,文章提出了一种基于决策面几何关系的移动方法以确定移动的方向。
对抗性样本采样(Adversarial Example Sampling):构造了具有一定攻击成功率保证的对抗性分布后,攻击者可通过随机采样的方式无限生成独立的高成功率的攻击样本。与此同时,攻击者可采取实践性攻击的方式,在短时间内采样攻击样本query目标模型,直到攻击成功。
实验结果
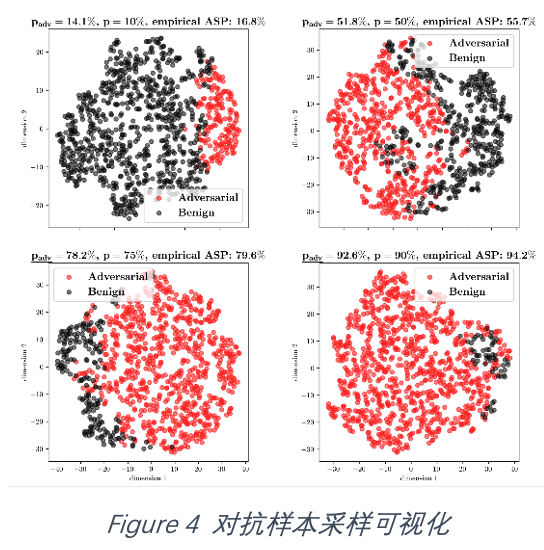
1. 对抗性分布的效果如何?保证的理论攻击成功概率和实际的攻击成功概率是否有差距?
如图4所示,该文展示了不同攻击成功概率阈值
2. 可验证黑盒攻击在攻击效率和访问效率上能否超过实践性黑盒攻击?在前沿的防御下,可验证黑盒攻击能否获得更好的表现?
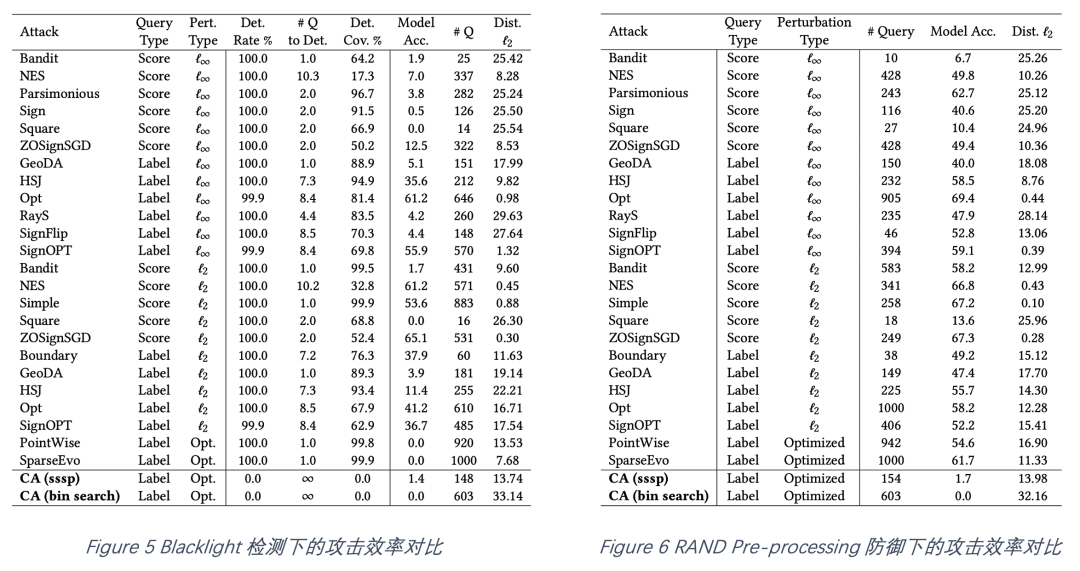

如图5-8所示,该文章对比了可验证攻击(CA)在四种强力防御下的攻击性能表现(图5-7为ImageNet数据集,图8为CIFAR10数据集)。图5显示,在Blacklight检测下,可验证攻击保持0%的检测率,而所有实践性攻击的检测率至少为99.9%。同时可验证攻击导致模型分类准确率下降至最多1.4%,且与实践性攻击保持相近的访问次数和扰动大小。图6-7显示,在加入了噪声的防御下,可验证攻击在保持合理的访问次数与扰动大小的前提下,攻击成功率超过大部分实践性攻击(模型分类准确率下降至~1%)。图8显示,在相对较小的访问次数与合理的扰动大小下,可验证攻击的攻击成功率超过大部分实践性攻击,特别是采用了二值搜索定位的可验证攻击在所有情况下可将模型分类准确率降低至0%。总体来说,可验证攻击在不同防御设定下,较实践性攻击均获得了更好的表现。
3. 该文章提出的可验证攻击框架下的各个方法的效果如何?文章中对提出的子方法均做了消融实验以验证其有效性,同时也做了大量实验衡量不同参数对攻击效果的影响。
4.如何防御可验证攻击?现有的其他防御或者可能的适应性防御的表现如何?文章在这一方面也做了大量实验,包括噪声检测防御、去噪声防御、随机平滑防御、对抗样本检测以及可能的白盒适应性防御。实验结果表明,现有的防御均不能显著降低可验证攻击成功率。
论文pdf:https://arxiv.org/pdf/2304.04343
个人主页:https://youbin2014.github.io/