Chapter 16 数组
数组是在内存中连续排列的一组变量,这些变量具有相同类型1。
16.1 小例子
#include <stdio.h>
int main()
{
int a[20];
int i;
for (i=0; i<20; i++)
a[i]=i*2;
for (i=0; i<20; i++)
printf ("a[%d]=%d
", i, a[i]);
return 0;
};
16.1.1 x86
编译后:
Listing 16.1: MSVC
_TEXT SEGMENT
_i$ = -84 ; size = 4
_a$ = -80 ; size = 80
_main PROC
push ebp
mov ebp, esp
sub esp, 84 ; 00000054H
mov DWORD PTR _i$[ebp], 0
jmp SHORT $LN6@main
$LN5@main:
mov eax, DWORD PTR _i$[ebp]
add eax, 1
mov DWORD PTR _i$[ebp], eax
$LN6@main:
cmp DWORD PTR _i$[ebp], 20 ; 00000014H
jge SHORT $LN4@main
mov ecx, DWORD PTR _i$[ebp]
shl ecx, 1
mov edx, DWORD PTR _i$[ebp]
mov DWORD PTR _a$[ebp+edx*4], ecx
jmp SHORT $LN5@main
$LN4@main:
mov DWORD PTR _i$[ebp], 0
jmp SHORT $LN3@main
$LN2@main:
mov eax, DWORD PTR _i$[ebp]
add eax, 1
mov DWORD PTR _i$[ebp], eax
$LN3@main:
cmp DWORD PTR _i$[ebp], 20 ; 00000014H
jge SHORT $LN1@main
mov ecx, DWORD PTR _i$[ebp]
mov edx, DWORD PTR _a$[ebp+ecx*4]
push edx
mov eax, DWORD PTR _i$[ebp]
push eax
push OFFSET $SG2463
call _printf
add esp, 12 ; 0000000cH
jmp SHORT $LN2@main
$LN1@main:
xor eax, eax
mov esp, ebp
pop ebp
ret 0
_main ENDP
这段代码主要有两个循环:第一个循环填充数组,第二个循环打印数组元素。shl ecx,1指令使ecx的值乘以2,更多关于左移请参考17.3.1。 在堆栈上为数组分配了80个字节的空间,包含20个元素,每个元素4字节大小。
GCC 4.4.1编译后为:
Listing 16.2: GCC 4.4.1
public main
main proc near ; DATA XREF: _start+17
var_70 = dword ptr -70h
var_6C = dword ptr -6Ch
var_68 = dword ptr -68h
i_2 = dword ptr -54h
i = dword ptr -4
push ebp
mov ebp, esp
and esp, 0FFFFFFF0h
sub esp, 70h
mov [esp+70h+i], 0 ; i=0
jmp short loc_804840A
loc_80483F7:
mov eax, [esp+70h+i]
mov edx, [esp+70h+i]
add edx, edx ; edx=i*2
mov [esp+eax*4+70h+i_2], edx
add [esp+70h+i], 1 ; i++
loc_804840A:
cmp [esp+70h+i], 13h
jle short loc_80483F7
mov [esp+70h+i], 0
jmp short loc_8048441
loc_804841B:
mov eax, [esp+70h+i]
mov edx, [esp+eax*4+70h+i_2]
mov eax, offset aADD ; "a[%d]=%d
"
mov [esp+70h+var_68], edx
mov edx, [esp+70h+i]
mov [esp+70h+var_6C], edx
mov [esp+70h+var_70], eax
call _printf
add [esp+70h+i], 1
loc_8048441:
cmp [esp+70h+i], 13h
jle short loc_804841B
mov eax, 0
leave
retn
main endp
顺便提一下,一个int*类型(指向int的指针)的变量—你可以使该变量指向数组并将该数组传递给另一个函数,更准确的说,传递的指针指向数组的第一个元素(该数组其它元素的地址需要显示计算)。比如a[idx],idx加上指向该数组的指针并返回该元素。 一个有趣的例子:类似”string”字符数组的类型是const char*,索引可以应用与该指针。比如可能写作”string”[i]—正确的C/C++表达式。
16.1.2 ARM + Non-optimizing Keil + ARM mode
EXPORT _main
_main
STMFD SP!, {R4,LR}
SUB SP, SP, #0x50 ; allocate place for 20 int variables
; first loop
MOV R4, #0 ; i
B loc_4A0
loc_494
MOV R0, R4,LSL#1 ; R0=R4*2
STR R0, [SP,R4,LSL#2] ; store R0 to SP+R4<<2 (same as SP+R4*4)
ADD R4, R4, #1 ; i=i+1
loc_4A0
CMP R4, #20 ; i<20?
BLT loc_494 ; yes, run loop body again
; second loop
MOV R4, #0 ; i
B loc_4C4
loc_4B0
LDR R2, [SP,R4,LSL#2] ; (second printf argument) R2=*(SP+R4<<4) (same as *(SP+R4*4))
MOV R1, R4 ; (first printf argument) R1=i
ADR R0, aADD ; "a[%d]=%d
"
BL __2printf
ADD R4, R4, #1 ; i=i+1
loc_4C4
CMP R4, #20 ; i<20?
BLT loc_4B0 ; yes, run loop body again
MOV R0, #0 ; value to return
ADD SP, SP, #0x50 ; deallocate place, allocated for 20 int variables
LDMFD SP!, {R4,PC}
int类型长度为32bits即4字节,20个int变量需要80(0x50)字节,因此“sub sp,sp,#0x50”指令为在栈上分配存储空间。 两个循环迭代器i被存储在R4寄存器中。 值i*2被写入数组,通过将i值左移1位实现乘以2的效果,整个过程通过”MOV R0,R4,LSL#1指令来实现。 “STR R0, [SP,R4,LSL#2]”把R0内容写入数组。过程为:SP指向数组开始,R4是i,i左移2位相当于乘以4,即*(SP+R4*4)=R0。 第二个loop的“LDR R2, [SP,R4,LSL#2]”从数组读取数值到寄存器,R2=*(SP+R4*4)。
16.1.3 ARM + Keil + thumb 模式优化后
_main
PUSH {R4,R5,LR}
; allocate place for 20 int variables + one more variable
SUB SP, SP, #0x54
; first loop
MOVS R0, #0 ; i
MOV R5, SP ; pointer to first array element
loc_1CE
LSLS R1, R0, #1 ; R1=i<<1 (same as i*2)
LSLS R2, R0, #2 ; R2=i<<2 (same as i*4)
ADDS R0, R0, #1 ; i=i+1
CMP R0, #20 ; i<20?
STR R1, [R5,R2] ; store R1 to *(R5+R2) (same R5+i*4)
BLT loc_1CE ; yes, i<20, run loop body again
; second loop
MOVS R4, #0 ; i=0
loc_1DC
LSLS R0, R4, #2 ; R0=i<<2 (same as i*4)
LDR R2, [R5,R0] ; load from *(R5+R0) (same as R5+i*4)
MOVS R1, R4
ADR R0, aADD ; "a[%d]=%d
"
BL __2printf
ADDS R4, R4, #1 ; i=i+1
CMP R4, #20 ; i<20?
BLT loc_1DC ; yes, i<20, run loop body again
MOVS R0, #0 ; value to return
; deallocate place, allocated for 20 int variables + one more variable
ADD SP, SP, #0x54
POP {R4,R5,PC}
Thumb代码也是非常类似的。Thumb模式计算数组偏移的移位操作使用特定的指令LSLS。 编译器在堆栈中申请的数组空间更大,但是最后4个字节的空间未使用。
16.2 缓冲区溢出
Array[index]中index指代数组索引,仔细观察下面的代码,你可能注意到代码没有index是否小于20。如果index大于20?这是C/C++经常被批评的特征。 以下代码可以成功编译可以工作:
#include <stdio.h>
int main()
{
int a[20];
int i;
for (i=0; i<20; i++)
a[i]=i*2;
printf ("a[100]=%d
", a[100]);
return 0;
};
编译后 (MSVC 2010):
_TEXT SEGMENT
_i$ = -84 ; size = 4
_a$ = -80 ; size = 80
_main PROC
push ebp
mov ebp, esp
sub esp, 84 ; 00000054H
mov DWORD PTR _i$[ebp], 0
jmp SHORT $LN3@main
$LN2@main:
mov eax, DWORD PTR _i$[ebp]
add eax, 1
mov DWORD PTR _i$[ebp], eax
$LN3@main:
cmp DWORD PTR _i$[ebp], 20 ; 00000014H
jge SHORT $LN1@main
mov ecx, DWORD PTR _i$[ebp]
shl ecx, 1
mov edx, DWORD PTR _i$[ebp]
mov DWORD PTR _a$[ebp+edx*4], ecx
jmp SHORT $LN2@main
$LN1@main:
mov eax, DWORD PTR _a$[ebp+400]
push eax
push OFFSET $SG2460
call _printf
add esp, 8
xor eax, eax
mov esp, ebp
pop ebp
ret 0
_main ENDP
运行,我们得到:a[100]=760826203
打印的数字仅仅是距离数组第一个元素400个字节处的堆栈上的数值。 编译器可能会自动添加一些判断数组边界的检测代码(更高级语言3),但是这可能影响运行速度。 我们可以从栈上非法读取数值,是否可以写入数值呢? 下面我们将写入数值:
#include <stdio.h>
int main()
{
int a[20];
int i;
for (i=0; i<30; i++)
a[i]=i;
return 0;
};
我们得到:
_TEXT SEGMENT
_i$ = -84 ; size = 4
_a$ = -80 ; size = 80
_main PROC
push ebp
mov ebp, esp
sub esp, 84 ; 00000054H
mov DWORD PTR _i$[ebp], 0
jmp SHORT $LN3@main
$LN2@main:
mov eax, DWORD PTR _i$[ebp]
add eax, 1
mov DWORD PTR _i$[ebp], eax
$LN3@main:
cmp DWORD PTR _i$[ebp], 30 ; 0000001eH
jge SHORT $LN1@main
mov ecx, DWORD PTR _i$[ebp]
mov edx, DWORD PTR _i$[ebp] ; that instruction is obviously redundant
mov DWORD PTR _a$[ebp+ecx*4], edx ; ECX could be used as second operand here instead
jmp SHORT $LN2@main
$LN1@main:
xor eax, eax
mov esp, ebp
pop ebp
ret 0
_main ENDP
编译后运行,程序崩溃。我们找出导致崩溃的地方。 没有使用调试器,而是使用我自己写的小工具tracer足以完成任务。 我们用它看被调试进程崩溃的地方:
generic tracer 0.4 (WIN32), http://conus.info/gt
New process: C:PRJ...1.exe, PID=7988
EXCEPTION_ACCESS_VIOLATION: 0x15 (<symbol (0x15) is in unknown module>), ExceptionInformation
[0]=8
EAX=0x00000000 EBX=0x7EFDE000 ECX=0x0000001D EDX=0x0000001D
ESI=0x00000000 EDI=0x00000000 EBP=0x00000014 ESP=0x0018FF48
EIP=0x00000015
FLAGS=PF ZF IF RF
PID=7988|Process exit, return code -1073740791
我们来看各个寄存器的状态,异常发生在地址0x15。这是个非法地址—至少对win32代码来说是!这种情况并不是我们期望的,我们还可以看到EBP值为0x14,ECX和EDX都为0x1D。 让我们来研究堆栈布局。 代码进入main()后,EBP寄存器的值被保存在栈上。为数组和变量i一共分配84字节的栈空间,即(20+1)*sizeof(int)。此时ESP指向_i变量,之后执行push something,something将紧挨着_i。 此时main()函数内栈布局为:
ESP
ESP+4
ESP+84
ESP+88
4 bytes for i
80 bytes for a[20] array
saved EBP value
returning address
指令a[19]=something写入最后的int到数组边界(这里是数组边界!)。 指令a[20]=something,something将覆盖栈上保存的EBP值。 请注意崩溃时寄存器的状态。在此例中,数字20被写入第20个元素,即原来存放EBP值得地方被写入了20(20的16进制表示是0x14)。然后RET指令被执行,相当于执行POP EIP指令。 RET指令从堆栈中取出返回地址(该地址为CRT内部调用main()的地址),返回地址处被存储了21(0x15)。CPU执行地址0x15的代码,异常被抛出。 Welcome!这被称为缓冲区溢出4。 使用字符数组代替int数组,创建一个较长的字符串,把字符串传递给程序,函数没有检测字符串长度,把字符复制到较短的缓冲区,你能够找到找到程序必须跳转的地址。事实上,找出它们并不是很简单。 我们来看GCC 4.4.1编译后的同类代码:
public main
main proc near
a = dword ptr -54h
i = dword ptr -4
push ebp
mov ebp, esp
sub esp, 60h
mov [ebp+i], 0
jmp short loc_80483D1
loc_80483C3:
mov eax, [ebp+i]
mov edx, [ebp+i]
mov [ebp+eax*4+a], edx
add [ebp+i], 1
loc_80483D1:
cmp [ebp+i], 1Dh
jle short loc_80483C3
mov eax, 0
leave
retn
main endp
在linux下运行将产生:段错误。 使用GDB调试:
(gdb) r
Starting program: /home/dennis/RE/1
Program received signal SIGSEGV, Segmentation fault.
0x00000016 in ?? ()
(gdb) info registers
eax 0x0 0
ecx 0xd2f96388 -755407992
edx 0x1d 29
ebx 0x26eff4 2551796
esp 0xbffff4b0 0xbffff4b0
ebp 0x15 0x15
esi 0x0 0
edi 0x0 0
eip 0x16 0x16
eflags 0x10202 [ IF RF ]
cs 0x73 115
ss 0x7b 123
ds 0x7b 123
es 0x7b 123
fs 0x0 0
gs 0x33 51
(gdb)
寄存器的值与win32例子略微不同,因为堆栈布局也不太一样。
16.3 防止缓冲区溢出的方法
下面一些方法防止缓冲区溢出。MSVC使用以下编译选项:
/RTCs Stack Frame runtime checking
/GZ Enable stack checks (/RTCs)
一种方法是在函数局部变量和序言之间写入随机值。在函数退出之前检查该值。如果该值不一致则挂起而不执行RET。进程将被挂起。 该随机值有时被称为“探测值”。 如果使用MSVC编译简单的例子(16.1),使用RTC1和RTCs选项,将能看到函数调用@_RTC_CheckStackVars@8函数来检测“探测值“。
我们来看GCC如何处理这些。我们使用alloca()(4.2.4)例子:
#include <malloc.h>
#include <stdio.h>
void f()
{
char *buf=(char*)alloca (600);
_snprintf (buf, 600, "hi! %d, %d, %d
", 1, 2, 3);
puts (buf);
};
我们不使用任何附加编译选项,只使用默认选项,GCC 4.7.3将插入“探测“检测代码: Listing 16.3: GCC 4.7.3
.LC0:
.string "hi! %d, %d, %d
"
f:
push ebp
mov ebp, esp
push ebx
sub esp, 676
lea ebx, [esp+39]
and ebx, -16
mov DWORD PTR [esp+20], 3
mov DWORD PTR [esp+16], 2
mov DWORD PTR [esp+12], 1
mov DWORD PTR [esp+8], OFFSET FLAT:.LC0 ; "hi! %d, %d, %d
"
mov DWORD PTR [esp+4], 600
mov DWORD PTR [esp], ebx
mov eax, DWORD PTR gs:20 ; canary
mov DWORD PTR [ebp-12], eax
xor eax, eax
call _snprintf
mov DWORD PTR [esp], ebx
call puts
mov eax, DWORD PTR [ebp-12]
xor eax, DWORD PTR gs:20 ; canary
jne .L5
mov ebx, DWORD PTR [ebp-4]
leave
ret
.L5:
call __stack_chk_fail
随机值存在于gs:20。它被写入到堆栈,在函数的结尾与gs:20的探测值对比,如果不一致,__stack_chk_fail函数将被调用,控制台(Ubuntu 13.04 x86)将输出以下信息:
*** buffer overflow detected ***: ./2_1 terminated
======= Backtrace: =========
/lib/i386-linux-gnu/libc.so.6(__fortify_fail+0x63)[0xb7699bc3]
/lib/i386-linux-gnu/libc.so.6(+0x10593a)[0xb769893a]
/lib/i386-linux-gnu/libc.so.6(+0x105008)[0xb7698008]
/lib/i386-linux-gnu/libc.so.6(_IO_default_xsputn+0x8c)[0xb7606e5c]
/lib/i386-linux-gnu/libc.so.6(_IO_vfprintf+0x165)[0xb75d7a45]
/lib/i386-linux-gnu/libc.so.6(__vsprintf_chk+0xc9)[0xb76980d9]
/lib/i386-linux-gnu/libc.so.6(__sprintf_chk+0x2f)[0xb7697fef]
./2_1[0x8048404]
/lib/i386-linux-gnu/libc.so.6(__libc_start_main+0xf5)[0xb75ac935]
======= Memory map: ========
08048000-08049000 r-xp 00000000 08:01 2097586 /home/dennis/2_1
08049000-0804a000 r--p 00000000 08:01 2097586 /home/dennis/2_1
0804a000-0804b000 rw-p 00001000 08:01 2097586 /home/dennis/2_1
094d1000-094f2000 rw-p 00000000 00:00 0 [heap]
b7560000-b757b000 r-xp 00000000 08:01 1048602 /lib/i386-linux-gnu/libgcc_s.so.1
b757b000-b757c000 r--p 0001a000 08:01 1048602 /lib/i386-linux-gnu/libgcc_s.so.1
b757c000-b757d000 rw-p 0001b000 08:01 1048602 /lib/i386-linux-gnu/libgcc_s.so.1
b7592000-b7593000 rw-p 00000000 00:00 0
b7593000-b7740000 r-xp 00000000 08:01 1050781 /lib/i386-linux-gnu/libc-2.17.so
b7740000-b7742000 r--p 001ad000 08:01 1050781 /lib/i386-linux-gnu/libc-2.17.so
b7742000-b7743000 rw-p 001af000 08:01 1050781 /lib/i386-linux-gnu/libc-2.17.so
b7743000-b7746000 rw-p 00000000 00:00 0
b775a000-b775d000 rw-p 00000000 00:00 0
b775d000-b775e000 r-xp 00000000 00:00 0 [vdso]
b775e000-b777e000 r-xp 00000000 08:01 1050794 /lib/i386-linux-gnu/ld-2.17.so
b777e000-b777f000 r--p 0001f000 08:01 1050794 /lib/i386-linux-gnu/ld-2.17.so
b777f000-b7780000 rw-p 00020000 08:01 1050794 /lib/i386-linux-gnu/ld-2.17.so
bff35000-bff56000 rw-p 00000000 00:00 0 [stack]
Aborted (core dumped)
gs被叫做段寄存器,这些寄存器被广泛用在MS-DOS和扩展DOS时代。现在的作用和以前不同。简要的说,gs寄存器在linux下一直指向TLS(48)--存储线程的各种信息(win32环境下,fs寄存器同样的作用,指向TIB8 9)。 更多信息请参考linux源码arch/x86/include/asm/stackprotector.h(至少3.11版本)。
16.3.1 Optimizing Xcode (LLVM) + thumb-2 mode
我们回头看简单的数组例子(16.1)。我们来看LLVM如何检查“探测值“。
_main
var_64 = -0x64
var_60 = -0x60
var_5C = -0x5C
var_58 = -0x58
var_54 = -0x54
var_50 = -0x50
var_4C = -0x4C
var_48 = -0x48
var_44 = -0x44
var_40 = -0x40
var_3C = -0x3C
var_38 = -0x38
var_34 = -0x34
var_30 = -0x30
var_2C = -0x2C
var_28 = -0x28
var_24 = -0x24
var_20 = -0x20
var_1C = -0x1C
var_18 = -0x18
canary = -0x14
var_10 = -0x10
PUSH {R4-R7,LR}
ADD R7, SP, #0xC
STR.W R8, [SP,#0xC+var_10]!
SUB SP, SP, #0x54
MOVW R0, #aObjc_methtype ; "objc_methtype"
MOVS R2, #0
MOVT.W R0, #0
MOVS R5, #0
ADD R0, PC
LDR.W R8, [R0]
LDR.W R0, [R8]
STR R0, [SP,#0x64+canary]
MOVS R0, #2
STR R2, [SP,#0x64+var_64]
STR R0, [SP,#0x64+var_60]
MOVS R0, #4
STR R0, [SP,#0x64+var_5C]
MOVS R0, #6
STR R0, [SP,#0x64+var_58]
MOVS R0, #8
STR R0, [SP,#0x64+var_54]
MOVS R0, #0xA
STR R0, [SP,#0x64+var_50]
MOVS R0, #0xC
STR R0, [SP,#0x64+var_4C]
MOVS R0, #0xE
STR R0, [SP,#0x64+var_48]
MOVS R0, #0x10
STR R0, [SP,#0x64+var_44]
MOVS R0, #0x12
STR R0, [SP,#0x64+var_40]
MOVS R0, #0x14
STR R0, [SP,#0x64+var_3C]
MOVS R0, #0x16
STR R0, [SP,#0x64+var_38]
MOVS R0, #0x18
STR R0, [SP,#0x64+var_34]
MOVS R0, #0x1A
STR R0, [SP,#0x64+var_30]
MOVS R0, #0x1C
STR R0, [SP,#0x64+var_2C]
MOVS R0, #0x1E
STR R0, [SP,#0x64+var_28]
MOVS R0, #0x20
STR R0, [SP,#0x64+var_24]
MOVS R0, #0x22
STR R0, [SP,#0x64+var_20]
MOVS R0, #0x24
STR R0, [SP,#0x64+var_1C]
MOVS R0, #0x26
STR R0, [SP,#0x64+var_18]
MOV R4, 0xFDA ; "a[%d]=%d
"
MOV R0, SP
ADDS R6, R0, #4
ADD R4, PC
B loc_2F1C
; second loop begin
loc_2F14
ADDS R0, R5, #1
LDR.W R2, [R6,R5,LSL#2]
MOV R5, R0
loc_2F1C
MOV R0, R4
MOV R1, R5
BLX _printf
CMP R5, #0x13
BNE loc_2F14
LDR.W R0, [R8]
LDR R1, [SP,#0x64+canary]
CMP R0, R1
ITTTT EQ ; canary still correct?
MOVEQ R0, #0
ADDEQ SP, SP, #0x54
LDREQ.W R8, [SP+0x64+var_64],#4
POPEQ {R4-R7,PC}
BLX ___stack_chk_fail
首先可以看到,LLVM循环展开写入数组,LLVM认为先计算出数组元素的值速度更快。 在函数的结尾我们能看到“探测值“的检测—局部存储的值与R8指向的标准值对比。如果相等4指令块将通过”ITTTT EQ“触发,R0写入0,函数退出。如果不相等,指令块将不会被触发,跳向___stack_chk_fail函数,结束进程。
16.4 One more word about arrays
现在我们来理解下面的C/C++代码为什么不能正常使用10:
void f(int size)
{
int a[size];
...
};
这是因为在编译阶段编译器不知道数组的具体大小无论是在堆栈或者数据段,无法分配具体空间。 如果你需要任意大小的数组,应该通过malloc()分配空间,然后访问内存块来访问你需要的类型数组。或者使用C99标准[15,6.7.5/2],但它内部看起来更像alloca()(4.2.4)。
16.5 Multidimensional arrays
多维数组和线性数组在本质上是一样的。 因为计算机内存是线性的,它是一维数组。但是一维数组可以很容易用来表现多维的。 比如数组a[3][4]元素可以放置在一维数组的12个单元中:
[0][0]
[0][1]
[0][2]
[0][3]
[1][0]
[1][4]
[1][5]
[1][6]
[2][0]
[2][7]
[2][8]
[2][9]
该二维数组在内存中用一维数组索引表示为:
| 1 | 2 | 3 | |
|---|---|---|---|
| 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 |
为了计算我们需要的元素地址,首先,第一个索引乘以4(矩阵宽度),然后加上第二个索引。这种被称为行优先,C/C++和Python常用这种方法。行优先的意思是:先写入第一行,接着是第二行,…,最后是最后一行。 另一种方法就是列优先,主要用在FORTRAN,MATLAB,R等。列优先的意思是:先写入第一列,然后是第二列,…,最后是最后一列。 多维数组与此类似。 我们看个例子: Listing 16.4: simple example
#include <stdio.h>
int a[10][20][30];
void insert(int x, int y, int z, int value)
{
a[x][y][z]=value;
};
16.5.1 x86
MSVC 2010:
Listing 16.5: MSVC 2010
_DATA SEGMENT
COMM _a:DWORD:01770H
_DATA ENDS
PUBLIC _insert
_TEXT SEGMENT
_x$ = 8 ; size = 4
_y$ = 12 ; size = 4
_z$ = 16 ; size = 4
_value$ = 20 ; size = 4
_insert PROC
push ebp
mov ebp, esp
mov eax, DWORD PTR _x$[ebp]
imul eax, 2400 ; eax=600*4*x
mov ecx, DWORD PTR _y$[ebp]
imul ecx, 120 ; ecx=30*4*y
lea edx, DWORD PTR _a[eax+ecx] ; edx=a + 600*4*x + 30*4*y
mov eax, DWORD PTR _z$[ebp]
mov ecx, DWORD PTR _value$[ebp]
mov DWORD PTR [edx+eax*4], ecx ; *(edx+z*4)=value
pop ebp
ret 0
_insert ENDP
_TEXT ENDS
多维数组计算索引公式:address=600*4*x+30*4*y+4z。因为int类型为32-bits(4字节),所以要乘以4。
Listing 16.6: GCC 4.4.1
public insert
insert proc near
x = dword ptr 8
y = dword ptr 0Ch
z = dword ptr 10h
value = dword ptr 14h
push ebp
mov ebp, esp
push ebx
mov ebx, [ebp+x]
mov eax, [ebp+y]
mov ecx, [ebp+z]
lea edx, [eax+eax] ; edx=y*2
mov eax, edx ; eax=y*2
shl eax, 4 ; eax=(y*2)<<4 = y*2*16 = y*32
sub eax, edx ; eax=y*32 - y*2=y*30
imul edx, ebx, 600 ; edx=x*600
add eax, edx ; eax=eax+edx=y*30 + x*600
lea edx, [eax+ecx] ; edx=y*30 + x*600 + z
mov eax, [ebp+value]
mov dword ptr ds:a[edx*4], eax ; *(a+edx*4)=value
pop ebx
pop ebp
retn
insert endp
GCC使用的不同的计算方法。为计算第一个操作值30y,GCC没有使用乘法指令。GCC的做法是:(???? + ????) ≪ 4 − (???? + ????) = (2????) ≪ 4 − 2???? = 2 ・ 16 ・ ???? − 2???? = 32???? − 2???? = 30????。因此30y的计算仅使用加法和移位操作,这样速度更快。
16.5.2 ARM + Non-optimizing Xcode (LLVM) + thumb mode
Listing 16.7: Non-optimizing Xcode (LLVM) + thumb mode
_insert
value = -0x10
z = -0xC
y = -8
x = -4
; allocate place in local stack for 4 values of int type
SUB SP, SP, #0x10
MOV R9, 0xFC2 ; a
ADD R9, PC
LDR.W R9, [R9]
STR R0, [SP,#0x10+x]
STR R1, [SP,#0x10+y]
STR R2, [SP,#0x10+z]
STR R3, [SP,#0x10+value]
LDR R0, [SP,#0x10+value]
LDR R1, [SP,#0x10+z]
LDR R2, [SP,#0x10+y]
LDR R3, [SP,#0x10+x]
MOV R12, 2400
MUL.W R3, R3, R12
ADD R3, R9
MOV R9, 120
MUL.W R2, R2, R9
ADD R2, R3
LSLS R1, R1, #2 ; R1=R1<<2
ADD R1, R2
STR R0, [R1] ; R1 - address of array element
; deallocate place in local stack, allocated for 4 values of int type
ADD SP, SP, #0x10
BX LR
非优化的LLVM代码在栈中保存了所有变量,这是冗余的。元素地址的计算我们通过公式已经找到了。
16.5.3 ARM + Optimizing Xcode (LLVM) + thumb mode
Listing 16.8: Optimizing Xcode (LLVM) + thumb mode
_insert
MOVW R9, #0x10FC
MOV.W R12, #2400
MOVT.W R9, #0
RSB.W R1, R1, R1,LSL#4 ; R1 - y. R1=y<<4 - y = y*16 - y = y*15
ADD R9, PC ; R9 = pointer to a array
LDR.W R9, [R9]
MLA.W R0, R0, R12, R9 ; R0 - x, R12 - 2400, R9 - pointer to a. R0=x*2400 + ptr to a
ADD.W R0, R0, R1,LSL#3 ; R0 = R0+R1<<3 = R0+R1*8 = x*2400 + ptr to a + y*15*8 =
; ptr to a + y*30*4 + x*600*4
STR.W R3, [R0,R2,LSL#2] ; R2 - z, R3 - value. address=R0+z*4 =
; ptr to a + y*30*4 + x*600*4 + z*4
BX LR
这里的小技巧没有使用乘法,使用移位、加减法等。 这里有个新指令RSB(逆向减法),该指令的意义是让第一个操作数像SUB第二个操作数一样可以应用LSL#4附加操作。“LDR.W R9, [R9]”类似于x86下的LEA指令(B.6.2),这里什么都没有做,是冗余的。显然,编译器没有优化它。
Chapter 17 位域
很多函数参数的输入标志使用了位域。当然,可以使用bool类型来替代,只是有点浪费。
17.1 Specific bit checking
17.1.1 x86
Win32 API 例子:
HANDLE fh;
fh=CreateFile ("file", GENERIC_WRITE | GENERIC_READ, FILE_SHARE_READ, NULL, OPEN_ALWAYS,
FILE_ATTRIBUTE_NORMAL, NULL);
MSVC 2010: Listing 17.1: MSVC 2010
push 0
push 128 ; 00000080H
push 4
push 0
push 1
push -1073741824 ; c0000000H
push OFFSET $SG78813
call DWORD PTR __imp__CreateFileA@28
mov DWORD PTR _fh$[ebp], eax
我们再查看WinNT.h:
Listing 17.2: WinNT.h
#define GENERIC_READ (0x80000000L)
#define GENERIC_WRITE (0x40000000L)
#define GENERIC_EXECUTE (0x20000000L)
#define GENERIC_ALL (0x10000000L)
容易看出GENERIC_READ | GENERIC_WRITE = 0x80000000 | 0x40000000 = 0xC0000000,该值作为CreateFile()1函数的第二个参数。 CreateFile()如何检查该标志呢? 以Windows XP SP3 x86为例,在kernel32.dll中查看CreateFileW检查该标志的代码片段: Listing 17.3: KERNEL32.DLL (Windows XP SP3 x86)
.text:7C83D429 test byte ptr [ebp+dwDesiredAccess+3], 40h
.text:7C83D42D mov [ebp+var_8], 1
.text:7C83D434 jz short loc_7C83D417
.text:7C83D436 jmp loc_7C810817
我们来看TEST指令,该指令并未检测整个第二个参数,仅检测关键的一个字节(ebp+dwDesiredAccess+3),检测0x40标志(这里代表GENERIC_WRITE标志)。 Test对两个参数(目标,源)执行AND逻辑操作,并根据结果设置标志寄存器,结果本身不会保存(CMP和SUB与此类似(6.6.1))。 该代码片段逻辑如下:
if ((dwDesiredAccess&0x40000000) == 0) goto loc_7C83D417
如果AND指令没有设置ZF位,JZ将不触发跳转。如果dwDesiredAccess不等于0x40000000,AND结果将是0,ZF位将会被设置,条件跳转将被触发。
我们在linux GCC 4.4.1下查看:
#include <stdio.h>
#include <fcntl.h>
void main()
{
int handle;
handle=open ("file", O_RDWR | O_CREAT);
};
我们得到: Listing 17.4: GCC 4.4.1
public main
main proc near
var_20 = dword ptr -20h
var_1C = dword ptr -1Ch
var_4 = dword ptr -4
push ebp
mov ebp, esp
and esp, 0FFFFFFF0h
sub esp, 20h
mov [esp+20h+var_1C], 42h
mov [esp+20h+var_20], offset aFile ; "file"
call _open
mov [esp+20h+var_4], eax
leave
retn
main endp
我们在libc.so.6库中查看open()函数,看到syscall: Listing 17.5: open() (libc.so.6)
.text:000BE69B mov edx, [esp+4+mode] ; mode
.text:000BE69F mov ecx, [esp+4+flags] ; flags
.text:000BE6A3 mov ebx, [esp+4+filename] ; filename
.text:000BE6A7 mov eax, 5
.text:000BE6AC int 80h ; LINUX - sys_open
因此open()对于标志位的检测在内核中。 对于linux2.6,当sys_open被调用时,最终传递到do_sys_open内核函数,然后进入do_filp_open()函数(该函数位于源码fs/namei.c中)。 除了通过堆栈传递参数,还可以通过寄存器传递方式,这种调用方式成为fastcall(47.3)。这种调用方式CPU不需要访问堆栈就可以直接读取参数的值,所以速度更快。GCC有编译选项regram2,可以设置通过寄存器传递的参数的个数。 Linux2.6内核编译附加选项为-mregram=33 4。 这意味着前3个参数通过EAX、EDX、ECX寄存器传递,剩余的参数通过堆栈传递。如果参数小于3,仅部分寄存器被使用。 我们下载linux内核2.6.31源码,在Ubuntu中编译:make vmlinux,在IDA中打开,找到do_filp_open()函数。在开始部分我们可以看到(注释个人添加): Listing 17.6:do_filp_open() (linux kernel 2.6.31)
do_filp_open proc near
...
push ebp
mov ebp, esp
push edi
push esi
push ebx
mov ebx, ecx
add ebx, 1
sub esp, 98h
mov esi, [ebp+arg_4] ; acc_mode (5th arg)
test bl, 3
mov [ebp+var_80], eax ; dfd (1th arg)
mov [ebp+var_7C], edx ; pathname (2th arg)
mov [ebp+var_78], ecx ; open_flag (3th arg)
jnz short loc_C01EF684
mov ebx, ecx ; ebx <- open_flag
GCC保存3个参数的值到堆栈。否则,可能会造成寄存器浪费。 我们来看代码片段: Listing 17.7: do_filp_open() (linux kernel 2.6.31)
loc_C01EF6B4: ; CODE XREF: do_filp_open+4F
test bl, 40h ; O_CREAT
jnz loc_C01EF810
mov edi, ebx
shr edi, 11h
xor edi, 1
and edi, 1
test ebx, 10000h
jz short loc_C01EF6D3
or edi, 2
O_CREAT宏等于0x40,如果open_flag为0x40,标志位被置1,接下来的JNZ指令将被触发。
17.1.2 ARM
Linux kernel3.8.0检测O_CREAT过程有点不同。 Listing 17.8: linux kernel 3.8.0
struct file *do_filp_open(int dfd, struct filename *pathname,
const struct open_flags *op)
{
... filp = path_openat(dfd, pathname, &nd, op, flags | LOOKUP_RCU); ... }
static struct file *path_openat(int dfd, struct filename *pathname,
struct nameidata *nd, const struct open_flags *op, int flags)
{
... error = do_last(nd, &path, file, op, &opened, pathname); ... } static int do_last(struct nameidata nd, struct path path, struct file file, const struct open_flags op, int opened, struct filename name) { ... if (!(open_flag & O_CREAT)) { ... error = lookup_fast(nd, path, &inode); ... } else { ... error = complete_walk(nd); } ... }
在IDA中查看ARM模式内核: Listing 17.9: do_last() (vmlinux)
...
.text:C0169EA8 MOV R9, R3 ; R3 - (4th argument) open_flag
...
.text:C0169ED4 LDR R6, [R9] ; R6 - open_flag
...
.text:C0169F68 TST R6, #0x40 ; jumptable C0169F00 default case
.text:C0169F6C BNE loc_C016A128
.text:C0169F70 LDR R2, [R4,#0x10]
.text:C0169F74 ADD R12, R4, #8
.text:C0169F78 LDR R3, [R4,#0xC]
.text:C0169F7C MOV R0, R4
.text:C0169F80 STR R12, [R11,#var_50]
.text:C0169F84 LDRB R3, [R2,R3]
.text:C0169F88 MOV R2, R8
.text:C0169F8C CMP R3, #0
.text:C0169F90 ORRNE R1, R1, #3
.text:C0169F94 STRNE R1, [R4,#0x24]
.text:C0169F98 ANDS R3, R6, #0x200000
.text:C0169F9C MOV R1, R12
.text:C0169FA0 LDRNE R3, [R4,#0x24]
.text:C0169FA4 ANDNE R3, R3, #1
.text:C0169FA8 EORNE R3, R3, #1
.text:C0169FAC STR R3, [R11,#var_54]
.text:C0169FB0 SUB R3, R11, #-var_38
.text:C0169FB4 BL lookup_fast
...
.text:C016A128 loc_C016A128 ; CODE XREF: do_last.isra.14+DC
.text:C016A128 MOV R0, R4
.text:C016A12C BL complete_walk
...
TST指令类似于x86下的TEST指令。 这段代码来自do_last()函数源码,有两个分支lookup_fast()和complete_walk()。这里O_CREAT宏也等于0x40。
17.2 Specific bit setting/clearing
例如:
#define IS_SET(flag, bit) ((flag) & (bit))
#define SET_BIT(var, bit) ((var) |= (bit))
#define REMOVE_BIT(var, bit) ((var) &= ~(bit))
int f(int a)
{
int rt=a;
SET_BIT (rt, 0x4000);
REMOVE_BIT (rt, 0x200);
return rt;
};
17.2.1 x86
MSVC 2010: Listing 17.10: MSVC 2010
_rt$ = -4 ; size = 4
_a$ = 8 ; size = 4
_f PROC
push ebp
mov ebp, esp
push ecx
mov eax, DWORD PTR _a$[ebp]
mov DWORD PTR _rt$[ebp], eax
mov ecx, DWORD PTR _rt$[ebp]
or ecx, 16384 ; 00004000H
mov DWORD PTR _rt$[ebp], ecx
mov edx, DWORD PTR _rt$[ebp]
and edx, -513 ; fffffdffH
mov DWORD PTR _rt$[ebp], edx
mov eax, DWORD PTR _rt$[ebp]
mov esp, ebp
pop ebp
ret 0
_f ENDP
OR指令添加一个或多个bit位而忽略了其余位。 AND用来重置一个bit位。 如果我们使用msvc编译,并且打开优化选项(/Ox),代码将会更短: Listing 17.11: Optimizing MSVC
_a$ = 8 ; size = 4
_f PROC
mov eax, DWORD PTR _a$[esp-4]
and eax, -513 ; fffffdffH
or eax, 16384 ; 00004000H
ret 0
_f ENDP
我们来看GCC 4.4.1无优化的代码:
public f
f proc near
var_4 = dword ptr -4
arg_0 = dword ptr 8
push ebp
mov ebp, esp
sub esp, 10h
mov eax, [ebp+arg_0]
mov [ebp+var_4], eax
or [ebp+var_4], 4000h
and [ebp+var_4], 0FFFFFDFFh
mov eax, [ebp+var_4]
leave
retn
f endp
MSVC未优化的代码有些冗余。 现在我们来看GCC打开优化选项-O3:
Listing 17.13: Optimizing GCC
public f
f proc near
arg_0 = dword ptr 8
push ebp
mov ebp, esp
mov eax, [ebp+arg_0]
pop ebp
or ah, 40h
and ah, 0FDh
retn
f endp
代码更短。值得注意的是编译器使用了AH寄存器-EAX寄存器8bit-15bit部分。

8086 16位CPU累加器被称为AX,包含两个8位部分-AL(低字节)和AH(高字节)。在80386下所有寄存器被扩展为32位,累加器被命名为EAX,为了保持兼容性,它的老的部分仍可以作为AX/AH/AL寄存器来访问。 因为所有的x86 CPU都兼容于16位CPU,所以老的16位操作码比32位操作码更短。”or ah,40h”指令仅复制3个字节比“or eax,04000h”需要复制5个字节甚至6个字节(如果第一个操作码不是EAX)更合理。 编译时候开启-O3并且设置regram=3生成的代码会更短。
Listing 17.14: Optimizing GCC
public f
f proc near
push ebp
or ah, 40h
mov ebp, esp
and ah, 0FDh
pop ebp
retn
f endp
事实上,第一个参数已经被加载到EAX了,所以可以直接使用了。值得注意的是,函数序言(push ebp/mov ebp,esp)和结语(pop ebp)很容易被忽略。GCC并没有优化掉这些代码。更短的代码可以使用内联函数(27)。
17.2.2 ARM + Optimizing Keil + ARM mode
Listing 17.15: Optimizing Keil + ARM mode
02 0C C0 E3 BIC R0, R0, #0x200
01 09 80 E3 ORR R0, R0, #0x4000
1E FF 2F E1 BX LR
BIC是“逻辑and“类似于x86下的AND。ORR是”逻辑or“类似于x86下的OR。
17.2.3 ARM + Optimizing Keil + thumb mode
Listing 17.16: Optimizing Keil + thumb mode
01 21 89 03 MOVS R1, 0x4000
08 43 ORRS R0, R1
49 11 ASRS R1, R1, #5 ; generate 0x200 and place to R1
88 43 BICS R0, R1
70 47 BX LR5
从0x4000右移生成0x200,采用移位使代码更简洁。
17.2.4 ARM + Optimizing Xcode (LLVM) + ARM mode
Listing 17.17: Optimizing Xcode (LLVM) + ARM mode
42 0C C0 E3 BIC R0, R0, #0x4200
01 09 80 E3 ORR R0, R0, #0x4000
1E FF 2F E1 BX LR
该代码由LLVM生成,从源码形式上看,看起来更像是:
REMOVE_BIT (rt, 0x4200);
SET_BIT (rt, 0x4000);
为什么是0x4200?可能是编译器构造的5,可能是编译器编译错误,但生成的代码是可用的。 更多编译器异常请参考相关资料(67)。 对于thumb模式,优化Xcode(LLVM)生成的代码相似。
17.3 Shifts
C/C++的移位操作通过<<和>>实现。 这里有一个例子函数,计算输入变量有多少个位被置为1.
#define IS_SET(flag, bit) ((flag) & (bit))
int f(unsigned int a)
{
int i;
int rt=0;
for (i=0; i<32; i++)
if (IS_SET (a, 1<<i))
rt++;
return rt;
};
在循环中,迭代计数从0到31,1<<i语句将计数从1到0x80000000。1<<i即1左移n位,将包含32位数字所有可能的bit位。每次移位仅有1位被置1,其它位均为0,IS_SET宏将判断a对应的位是否置1。
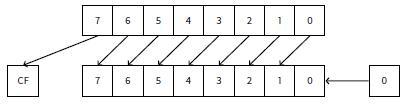
IS_SET宏就是逻辑与(AND)操作,如果对应的位不为1,则返回0。if条件表达式如果不为0,if()将被触发。
17.3.1 x86
MSVC 2010:
Listing 17.18: MSVC 2010
_rt$ = -8 ; size = 4
_i$ = -4 ; size = 4
_a$ = 8 ; size = 4
_f PROC
push ebp
mov ebp, esp
sub esp, 8
mov DWORD PTR _rt$[ebp], 0
mov DWORD PTR _i$[ebp], 0
jmp SHORT $LN4@f
$LN3@f:
mov eax, DWORD PTR _i$[ebp] ; increment of 1
add eax, 1
mov DWORD PTR _i$[ebp], eax
$LN4@f:
cmp DWORD PTR _i$[ebp], 32 ; 00000020H
jge SHORT $LN2@f ; loop finished?
mov edx, 1
mov ecx, DWORD PTR _i$[ebp]
shl edx, cl ; EDX=EDX<<CL
and edx, DWORD PTR _a$[ebp]
je SHORT $LN1@f ; result of AND instruction was 0?
; then skip next instructions
mov eax, DWORD PTR _rt$[ebp] ; no, not zero
add eax, 1 ; increment rt
mov DWORD PTR _rt$[ebp], eax
$LN1@f:
jmp SHORT $LN3@f
$LN2@f:
mov eax, DWORD PTR _rt$[ebp]
mov esp, ebp
pop ebp
ret 0
_f ENDP
下面是GCC 4.4.1编译的代码: Listing 17.19: GCC 4.4.1
public f
f proc near
rt = dword ptr -0Ch
i = dword ptr -8
arg_0 = dword ptr 8
push ebp
mov ebp, esp
push ebx
sub esp, 10h
mov [ebp+rt], 0
mov [ebp+i], 0
jmp short loc_80483EF
loc_80483D0:
mov eax, [ebp+i]
mov edx, 1
mov ebx, edx
mov ecx, eax
shl ebx, cl
mov eax, ebx
and eax, [ebp+arg_0]
test eax, eax
jz short loc_80483EB
add [ebp+rt], 1
loc_80483EB:
add [ebp+i], 1
loc_80483EF:
cmp [ebp+i], 1Fh
jle short loc_80483D0
mov eax, [ebp+rt]
add esp, 10h
pop ebx
pop ebp
retn
f endp
在乘以或者除以2的指数值(1,2,4,8等)时经常使用移位操作。 例如:
unsigned int f(unsigned int a)
{
return a/4;
};
MSVC 2010: Listing 17.20: MSVC 2010
_a$ = 8 ; size = 4
_f PROC
mov eax, DWORD PTR _a$[esp-4]
shr eax, 2
ret 0
_f ENDP
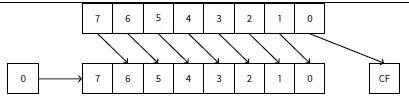
例子中的SHR(逻辑右移)指令将a值右移2位,最高两位被置0,最低2位被丢弃。实施上丢弃的两位是除法的余数。 SHR作用类似SHL只是移位方向不同。
使用十进制23很好来理解。23除以10,丢弃最后的数字(3是余数),商为2。 与此类似的是乘法。比如乘以4,仅需将数字左移2位,最低两位被置0。就像3乘以100—仅仅在最后补两个0就行了。
17.3.2 ARM + Optimizing Xcode (LLVM) + ARM mode
Listing 17.21: Optimizing Xcode (LLVM) + ARM mode
MOV R1, R0
MOV R0, #0
MOV R2, #1
MOV R3, R0
loc_2E54
TST R1, R2,LSL R3 ; set flags according to R1 & (R2<<R3)
ADD R3, R3, #1 ; R3++
ADDNE R0, R0, #1 ; if ZF flag is cleared by TST, R0++
CMP R3, #32
BNE loc_2E54
BX LR
TST类似于x86下的TEST指令。 正如我前面提到的(14.2.1),ARM模式下没有单独的移位指令。对于用作修饰的LSL(逻辑左移)、LSR(逻辑右移)、ASR(算术右移)、ROR(循环右移)和RRX(带扩展的循环右移指令),需要与MOV,TST,CMP,ADD,SUB,RSB结合来使用6。 这些修饰指令被定义,第二个操作数指定移动的位数。 因此“TST R1, R2,LSL R3”指令所做的工作为????1 ∧ (????2 ≪ ????3).
17.3.3 ARM + Optimizing Xcode (LLVM) + thumb-2 mode
几乎一样,只是这里使用LSL.W/TST指令而不是只有TST。因为Thumb模式下TST没有定义修饰符LSL。
MOV R1, R0
MOVS R0, #0
MOV.W R9, #1
MOVS R3, #0
loc_2F7A
LSL.W R2, R9, R3
TST R2, R1
ADD.W R3, R3, #1
IT NE
ADDNE R0, #1
CMP R3, #32
BNE loc_2F7A
BX LR
17.4 CRC32 calculation example
这是非常流行的CRC32哈希散列计算7。
/* By Bob Jenkins, (c) 2006, Public Domain */
#include <stdio.h>
#include <stddef.h>
#include <string.h>
typedef unsigned long ub4;
typedef unsigned char ub1;
static const ub4 crctab[256] = {
0x00000000, 0x77073096, 0xee0e612c, 0x990951ba, 0x076dc419, 0x706af48f,
0xe963a535, 0x9e6495a3, 0x0edb8832, 0x79dcb8a4, 0xe0d5e91e, 0x97d2d988,
0x09b64c2b, 0x7eb17cbd, 0xe7b82d07, 0x90bf1d91, 0x1db71064, 0x6ab020f2,
0xf3b97148, 0x84be41de, 0x1adad47d, 0x6ddde4eb, 0xf4d4b551, 0x83d385c7,
0x136c9856, 0x646ba8c0, 0xfd62f97a, 0x8a65c9ec, 0x14015c4f, 0x63066cd9,
0xfa0f3d63, 0x8d080df5, 0x3b6e20c8, 0x4c69105e, 0xd56041e4, 0xa2677172,
0x3c03e4d1, 0x4b04d447, 0xd20d85fd, 0xa50ab56b, 0x35b5a8fa, 0x42b2986c,
0xdbbbc9d6, 0xacbcf940, 0x32d86ce3, 0x45df5c75, 0xdcd60dcf, 0xabd13d59,
0x26d930ac, 0x51de003a, 0xc8d75180, 0xbfd06116, 0x21b4f4b5, 0x56b3c423,
0xcfba9599, 0xb8bda50f, 0x2802b89e, 0x5f058808, 0xc60cd9b2, 0xb10be924,
0x2f6f7c87, 0x58684c11, 0xc1611dab, 0xb6662d3d, 0x76dc4190, 0x01db7106,
0x98d220bc, 0xefd5102a, 0x71b18589, 0x06b6b51f, 0x9fbfe4a5, 0xe8b8d433,
0x7807c9a2, 0x0f00f934, 0x9609a88e, 0xe10e9818, 0x7f6a0dbb, 0x086d3d2d,
0x91646c97, 0xe6635c01, 0x6b6b51f4, 0x1c6c6162, 0x856530d8, 0xf262004e,
0x6c0695ed, 0x1b01a57b, 0x8208f4c1, 0xf50fc457, 0x65b0d9c6, 0x12b7e950,
0x8bbeb8ea, 0xfcb9887c, 0x62dd1ddf, 0x15da2d49, 0x8cd37cf3, 0xfbd44c65,
0x4db26158, 0x3ab551ce, 0xa3bc0074, 0xd4bb30e2, 0x4adfa541, 0x3dd895d7,
0xa4d1c46d, 0xd3d6f4fb, 0x4369e96a, 0x346ed9fc, 0xad678846, 0xda60b8d0,
0x44042d73, 0x33031de5, 0xaa0a4c5f, 0xdd0d7cc9, 0x5005713c, 0x270241aa,
0xbe0b1010, 0xc90c2086, 0x5768b525, 0x206f85b3, 0xb966d409, 0xce61e49f,
0x5edef90e, 0x29d9c998, 0xb0d09822, 0xc7d7a8b4, 0x59b33d17, 0x2eb40d81,
0xb7bd5c3b, 0xc0ba6cad, 0xedb88320, 0x9abfb3b6, 0x03b6e20c, 0x74b1d29a,
0xead54739, 0x9dd277af, 0x04db2615, 0x73dc1683, 0xe3630b12, 0x94643b84,
0x0d6d6a3e, 0x7a6a5aa8, 0xe40ecf0b, 0x9309ff9d, 0x0a00ae27, 0x7d079eb1,
0xf00f9344, 0x8708a3d2, 0x1e01f268, 0x6906c2fe, 0xf762575d, 0x806567cb,
0x196c3671, 0x6e6b06e7, 0xfed41b76, 0x89d32be0, 0x10da7a5a, 0x67dd4acc,
0xf9b9df6f, 0x8ebeeff9, 0x17b7be43, 0x60b08ed5, 0xd6d6a3e8, 0xa1d1937e,
0x38d8c2c4, 0x4fdff252, 0xd1bb67f1, 0xa6bc5767, 0x3fb506dd, 0x48b2364b,
0xd80d2bda, 0xaf0a1b4c, 0x36034af6, 0x41047a60, 0xdf60efc3, 0xa867df55,
0x316e8eef, 0x4669be79, 0xcb61b38c, 0xbc66831a, 0x256fd2a0, 0x5268e236,
0xcc0c7795, 0xbb0b4703, 0x220216b9, 0x5505262f, 0xc5ba3bbe, 0xb2bd0b28,
0x2bb45a92, 0x5cb36a04, 0xc2d7ffa7, 0xb5d0cf31, 0x2cd99e8b, 0x5bdeae1d,
0x9b64c2b0, 0xec63f226, 0x756aa39c, 0x026d930a, 0x9c0906a9, 0xeb0e363f,
0x72076785, 0x05005713, 0x95bf4a82, 0xe2b87a14, 0x7bb12bae, 0x0cb61b38,
0x92d28e9b, 0xe5d5be0d, 0x7cdcefb7, 0x0bdbdf21, 0x86d3d2d4, 0xf1d4e242,
0x68ddb3f8, 0x1fda836e, 0x81be16cd, 0xf6b9265b, 0x6fb077e1, 0x18b74777,
0x88085ae6, 0xff0f6a70, 0x66063bca, 0x11010b5c, 0x8f659eff, 0xf862ae69,
0x616bffd3, 0x166ccf45, 0xa00ae278, 0xd70dd2ee, 0x4e048354, 0x3903b3c2,
0xa7672661, 0xd06016f7, 0x4969474d, 0x3e6e77db, 0xaed16a4a, 0xd9d65adc,
0x40df0b66, 0x37d83bf0, 0xa9bcae53, 0xdebb9ec5, 0x47b2cf7f, 0x30b5ffe9,
0xbdbdf21c, 0xcabac28a, 0x53b39330, 0x24b4a3a6, 0xbad03605, 0xcdd70693,
0x54de5729, 0x23d967bf, 0xb3667a2e, 0xc4614ab8, 0x5d681b02, 0x2a6f2b94,
0xb40bbe37, 0xc30c8ea1, 0x5a05df1b, 0x2d02ef8d,
};
/* how to derive the values in crctab[] from polynomial 0xedb88320 */
void build_table()
{
ub4 i, j;
for (i=0; i<256; ++i) {
j = i;
j = (j>>1) ^ ((j&1) ? 0xedb88320 : 0);
j = (j>>1) ^ ((j&1) ? 0xedb88320 : 0);
j = (j>>1) ^ ((j&1) ? 0xedb88320 : 0);
j = (j>>1) ^ ((j&1) ? 0xedb88320 : 0);
j = (j>>1) ^ ((j&1) ? 0xedb88320 : 0);
j = (j>>1) ^ ((j&1) ? 0xedb88320 : 0);
j = (j>>1) ^ ((j&1) ? 0xedb88320 : 0);
j = (j>>1) ^ ((j&1) ? 0xedb88320 : 0);
printf("0x%.8lx, ", j);
if (i%6 == 5) printf("
");
}
}
/* the hash function */
ub4 crc(const void *key, ub4 len, ub4 hash)
{
ub4 i;
const ub1 *k = key;
for (hash=len, i=0; i<len; ++i)
hash = (hash >> 8) ^ crctab[(hash & 0xff) ^ k[i]];
return hash;
}
/* To use, try "gcc -O crc.c -o crc; crc < crc.c" */
int main()
{
char s[1000];
while (gets(s)) printf("%.8lx
", crc(s, strlen(s), 0));
return 0;
}
我们只关心crc()函数。注意for()语句两个循环初始化:hash=len,i=0。标准C/C++允许这样做。循环体内通常需要使用两个初始化部分。 让我们用MSVC优化(/Ox)。为了简洁,仅列出crc()函数的代码,包括我做的注释。
key$ = 8 ; size = 4
_len$ = 12 ; size = 4
_hash$ = 16 ; size = 4
_crc PROC
mov edx, DWORD PTR _len$[esp-4]
xor ecx, ecx ; i will be stored in ECX
mov eax, edx
test edx, edx
jbe SHORT $LN1@crc
push ebx
push esi
mov esi, DWORD PTR _key$[esp+4] ; ESI = key
push edi
$LL3@crc:
; work with bytes using only 32-bit registers. byte from address key+i we store into EDI
movzx edi, BYTE PTR [ecx+esi]
mov ebx, eax ; EBX = (hash = len)
and ebx, 255 ; EBX = hash & 0xff
; XOR EDI, EBX (EDI=EDI^EBX) - this operation uses all 32 bits of each register
; but other bits (8-31) are cleared all time, so it’s OK
; these are cleared because, as for EDI, it was done by MOVZX instruction above
; high bits of EBX was cleared by AND EBX, 255 instruction above (255 = 0xff)
xor edi, ebx
; EAX=EAX>>8; bits 24-31 taken "from nowhere" will be cleared
shr eax, 8
; EAX=EAX^crctab[EDI*4] - choose EDI-th element from crctab[] table
xor eax, DWORD PTR _crctab[edi*4]
inc ecx ; i++
cmp ecx, edx ; i<len ?
jb SHORT $LL3@crc ; yes
pop edi
pop esi
pop ebx
$LN1@crc:
ret 0
_crc ENDP
我们来看GCC 4.4.1优化后的代码:
public crc
crc proc near
key = dword ptr 8
hash = dword ptr 0Ch
push ebp
xor edx, edx
mov ebp, esp
push esi
mov esi, [ebp+key]
push ebx
mov ebx, [ebp+hash]
test ebx, ebx
mov eax, ebx
jz short loc_80484D3
nop ; padding
lea esi, [esi+0] ; padding; ESI doesn’t changing here
loc_80484B8:
mov ecx, eax ; save previous state of hash to ECX
xor al, [esi+edx] ; AL=*(key+i)
add edx, 1 ; i++
shr ecx, 8 ; ECX=hash>>8
movzx eax, al ; EAX=*(key+i)
mov eax, dword ptr ds:crctab[eax*4] ; EAX=crctab[EAX]
xor eax, ecx ; hash=EAX^ECX
cmp ebx, edx
ja short loc_80484B8
loc_80484D3:
pop ebx
pop esi
pop ebp
retn
crc endp
GCC在循环开始的时候通过填入NOP和lea esi,esi+0来按8字节对齐。更多信息请阅读npad小结(64)。